爬虫总结
个人的一些爬虫经验总结
关于请求: python中向网站发起请求的库有urllib, urlib2等,这两个应该是python解释器的默认库,我当时学习的时候却是由requests出发的,相较于前两个,requests是在它们之上再封装的,添加请求头等信息非常方便。 requests高度自由,适合个性化的小型爬虫。可以获得文本,图像,音频,视频等信息。
A bioinformation student
个人的一些爬虫经验总结
关于请求: python中向网站发起请求的库有urllib, urlib2等,这两个应该是python解释器的默认库,我当时学习的时候却是由requests出发的,相较于前两个,requests是在它们之上再封装的,添加请求头等信息非常方便。 requests高度自由,适合个性化的小型爬虫。可以获得文本,图像,音频,视频等信息。
爬取B站UP主信息

爬取网页,一般的做法是先直接向目标页面发起请求,然后返回,查看返回页面是否与目标页面相同,如果不同,则证明这个页面是动态加载页面,需要另寻它法。
爬取重庆市部分区县的二手房信息
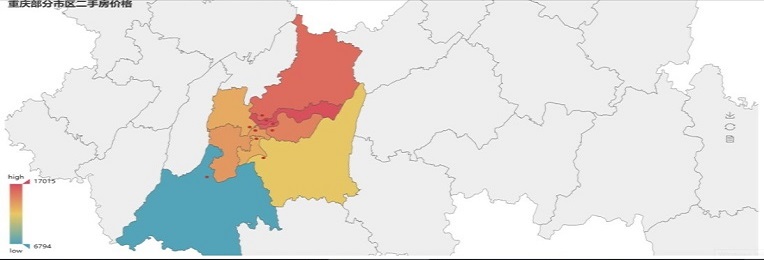
前段时间在实验楼上面看到有爬取链家网租房信息,并利用高德API在地图上标注上班周边区域房源的介绍,就想着做做看。当然,我没有那么高的姿势水平,就爬一下二手房信息得了。



Something to say