爬取链家二手房信息
爬取重庆市部分区县的二手房信息
前段时间在实验楼上面看到有爬取链家网租房信息,并利用高德API在地图上标注上班周边区域房源的介绍,就想着做做看。当然,我没有那么高的姿势水平,就爬一下二手房信息得了。
准备:python,requests(url访问),lxml(html解析), tdqm(好看的动态进度条), re(正则),pandas(数据分析), pyecharts(画地图)
第一次发爬虫文章, 就详细点吧。。。。。
一、向网站发送请求,对于一般的网站来说,这个其实是很固定的格式 向网站发送请求,得到页面信息
当时是按照北理工的公开课学的爬虫,就延续下来用的requests,当然还有其它的。
一些反扒网站比较严格,所以得另加一点东西,比如cookies,user-agent等等, 在这里我就换了一个请求头,让网站认为是一个浏览器而不是python在访问。
二、第一步得到的就是html页面了,然后就可以开始解析。这里我用的是xpath,当然也有其它的解析方式,比如我最初学的时候就用的beautifulsoup,但是现在全部忘完了, 最暴力的解析方式是正则,但是必须要有很高的技术才行,因为说不定就多爬或者少爬了点东西。xpath的好处在于浏览器安装插件后可以直接复制元素的xpath路径,很方便。 抓取网页页面个数
首先我抓取了页面总数的数字,以防在后续构建url的时候出错,这里一般都会有“下一页”这个按钮,也可以分析他的url。
然后就是抓取需要的信息了。浏览器直接复制xpath路径,简单暴力,但是注意的是,有时候复制的xpath路径得不到目标元素,这时就要自己修改了。抓取后对部分信息提取,比如抓取的是“25415元”,提取出“25415”这种类型,等等。处理好,返回。
抓取网页信息与处理 抓取网页信息与处理二
三、将上面的步骤整理, 构建主函数,写入硬盘。至此,数据就全部抓取完了,遗憾的是,链家网上只有重庆9个区的二手房信息。 拼接url,利用上面的函数得到数据
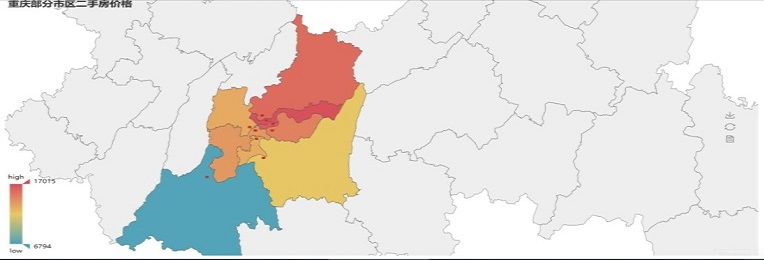
四、pandas处理下载的数据,简单求每个区的二手房价格平均值。并在地图上以热图的方式显示。由于不是一起做的,所以这里我另写了一个脚本来分析。 pandas分析和pyecharts作图
在得到的热图中,可以看到,渝中,渝北,江北的二手房的均价是比较高的,图片看不出来具体是多少,可以到百度云盘打开html查看,里面含代码。
下载二手房数据
# -*- coding: utf-8 -*-
import requests
import re
import time
from lxml import etree
from tqdm import tqdm
def get_html(url): # 向网站发送请求,代码格式固定
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
r = requests.get(url=url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return(r.text)
def get_last_page(url):
html = get_html(url)
selector = etree.HTML(html)
num_info = selector.xpath('/html/body/div[4]/div[1]/div[8]/div[2]/div/@page-data')
num = re.search("\d+", num_info[0]).group()
return(int(num))
def get_information(url): # 得到网页信息,并解析
html = get_html(url)
selector = etree.HTML(html) # xpath解析方式
# 得到想要的信息
house_title = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[1]/a/text()')
house_loupan = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[2]/div/a/text()')
house_informations = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[2]/div/text()')
house_floors = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[3]/div/text()')
house_loction = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[3]/div/a/text()')
house_price = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[6]/div[1]/span/text()')
house_per_price = selector.xpath('/html/body/div[4]/div[1]/ul/li/div[1]/div[6]/div[2]/span/text()')
# 对得到的信息做进一步处理
# 处理一, 对房子信息拆解
house_informations_list = []
for house_info in house_informations:
house_infos = house_info.split("|")
if (len(house_infos) != 6):
house_infos.append("-") # 部分没有列出电梯信息
squre = re.search("[^\u4e00-\u9fa5]+", house_infos[2]).group()
house_infos[2] = squre
if len(house_infos) != 6:
house_informations_list.append(["-", "-", "-", "-", "-", "-"])
else:
house_informations_list.append(house_infos)
# 处理二,房子单价提取
house_per_prices = []
for house_per in house_per_price:
new_house_per = re.search("\d+", house_per).group()
house_per_prices.append(new_house_per)
# 整理每一个元素,返回
house_all_information = []
print(house_informations)
for i in range(len(house_title)):
house_all_information.append(house_loction[i] + "\t" + house_title[i] + "\t" + house_loupan[i] + "\t" + house_informations_list[i][1] + "\t" + house_informations_list[i][2] + "\t" + house_informations_list[i][3] + "\t" + house_informations_list[i][4] + "\t" + house_informations_list[i][5] + "\t" + house_floors[i] + "\t" + house_per_prices[i] + "\t" + house_price[i])
return(house_all_information)
# 原始url, 并拼接
raw_url = "https://km.lianjia.com/ershoufang/"
citys = ["wuhua"]
for city in citys:
first_url = raw_url + city + "/pg1"
num = get_last_page(first_url)
raw_url1 = raw_url + city + "/pg"
urls = []
for i in range(num): #
urls.append(raw_url1 + str(i + 1))
# 写入文件house_information.txt
f = open("C:\\Users\\Lenovo\\Desktop\\python\\lianjia\\" + city + "_house_information.txt", "a", encoding='utf-8')
f.write("位置\t" + "标题\t" + "楼盘\t" + "厅室\t" + "面积(m2)\t" + "朝向\t" + "类型\t" + "电梯\t" + "楼层\t" + "单价(元)\t" + "总价(万元)\t\n")
print("开始爬取" + city + "的二手房信息。")
for url in tqdm(urls, leave=False):
house_all_information = get_information(url)
for i in house_all_information:
f.write(i+"\n")
time.sleep(1)
f.close()
print("Successfully download the information!")
f.close()
地图可视化
# -*- coding: utf-8 -*-
import pandas as pd
from pyecharts import Map
cities = ["jiangbei", "yubei", "yuzhong", "nanan", "banan", "jiulongpo", "shapingba", "dadukou", "jiangjing"]
def get_average_price(city):
data = pd.read_table("C:\\Users\\Lenovo\\Desktop\\lianjia\\data\\%s_house_information.txt"%city,sep="\t", header=0)
average_price = data["单价(元)"].mean()
return(average_price)
average_prices = []
for city in cities:
average_price = get_average_price(city)
average_prices.append(average_price)
attr = ['江北区', '渝北区', '渝中区', '南岸区', '巴南区', '九龙坡区', '沙坪坝区', '大渡口区', '江津区']
map = Map("重庆部分市区二手房价格",width=1200,height=600)
map.add("", attr, average_prices, maptype='重庆', visual_range=[min(average_prices) - 100, max(average_prices ) + 100], is_visualmap=True,visual_text_color='#000')
map.render("map.html")



Twitter
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email